01 · PROJETO TÉCNICO AUTORAL
Databricks Lakehouse Case
Arquitetura Lakehouse corporativa ponta a ponta utilizando Databricks, PySpark e Delta Lake com orquestração serverless, quality framework operacional, semantic layer analítica, replay handling, observabilidade de pipelines e governança operacional baseada em DAG.
✦ Destaques técnicos
Arquitetura Medalhão Bronze / Silver / Gold
Ingestion Log operacional com auditoria de carga
Quality Log centralizado para troubleshooting
Replay handling e prevenção de duplicidade
Enforcement de granularidade (grain validation)
Surrogate keys determinísticas
Semantic Layer analítica
Views executivas para BI
Tratamento de dados órfãos
Pipeline observável e rastreável
Evidências operacionais documentadas
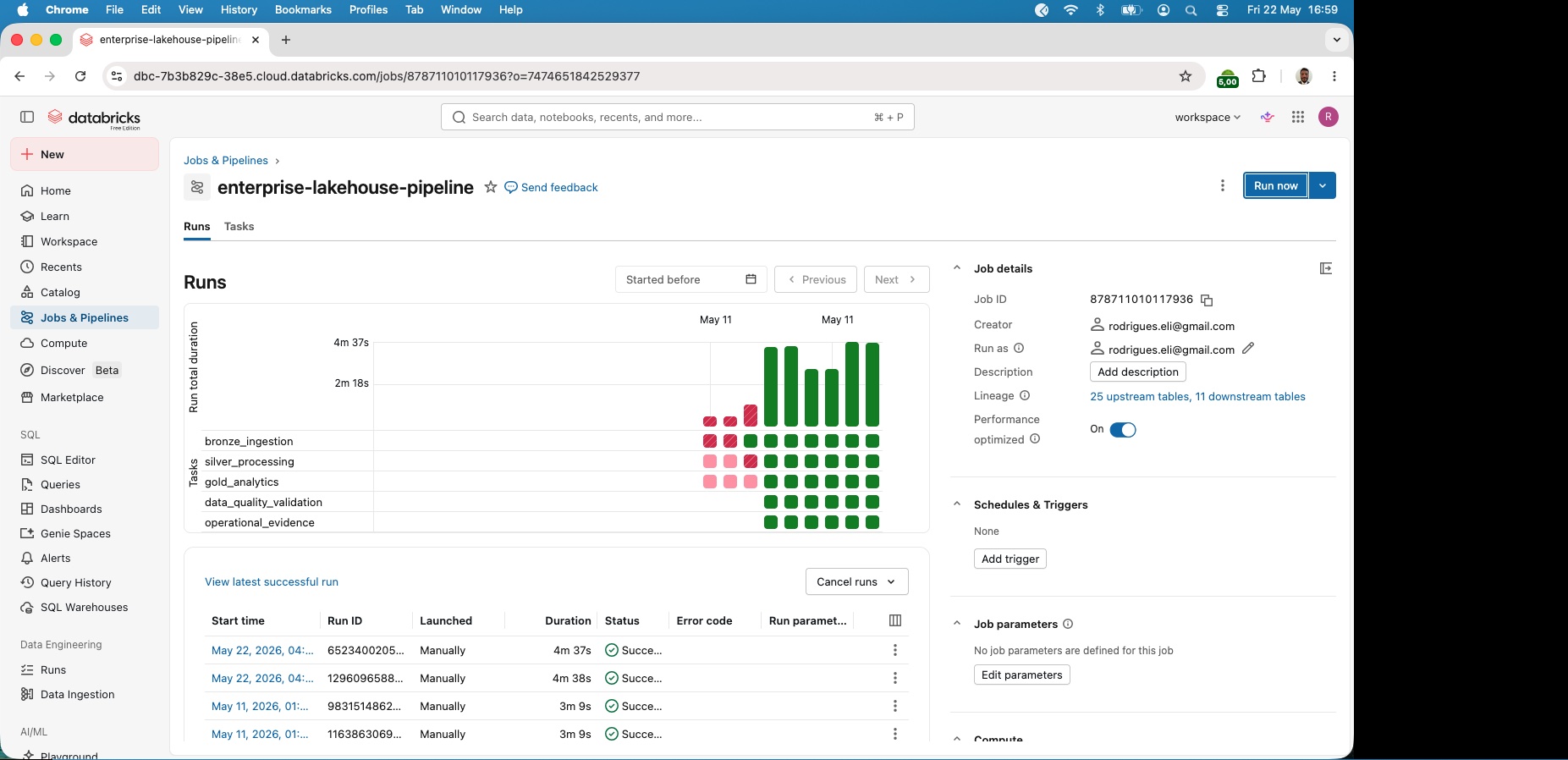
Orquestração ponta a ponta com Databricks Jobs
DAG serverless com dependência entre camadas
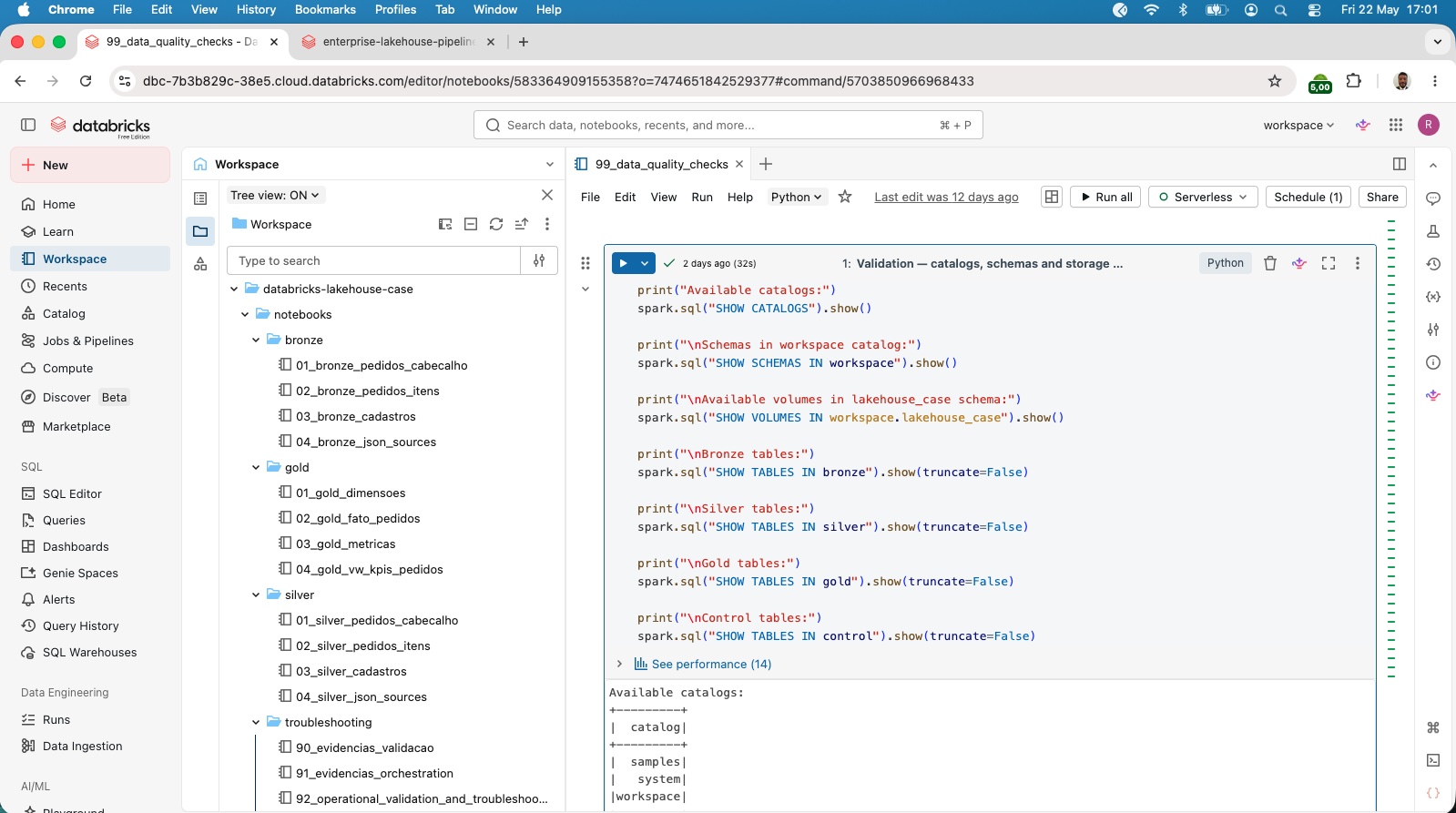
Data Quality Validation automatizado
Pipeline observável com execution evidence
Framework operacional de troubleshooting
Serverless pipeline orchestration
Controle operacional via ingestion_log
Quality framework centralizado
Pipeline execution monitoring
Evidências documentadas de execução Databricks
✦ Desafios resolvidos
Correção de replay/deduplicação em cargas incrementais
Tratamento de status inconsistentes
Normalização de chaves dimensionais
Identificação de registros órfãos
Garantia de grain único na fato
Rastreabilidade completa de falhas
Troubleshooting operacional com evidências documentadas
✦ Orquestração & Operação
Pipeline Bronze → Silver → Gold orquestrado
Databricks Jobs com DAG orientado a dependências
Execução serverless ponta a ponta
Data Quality Validation integrado ao pipeline
Observabilidade operacional da execução
Logs centralizados de ingestão e qualidade
Evidências operacionais documentadas
Execução rastreável com troubleshooting operacional
Projeto desenvolvido com foco em práticas de engenharia de dados corporativa, incluindo orquestração serverless, observabilidade operacional, governança de pipelines, data quality validation e troubleshooting operacional em arquitetura Lakehouse.